
Python SEO süreçlerini otomatikleştirmek için Python’u kullanmak, yeni kullanıcılar için göz korkutucu olabilir – en azından ilk başta. Bu sütunda, talimatları izleyerek kendi site(ler)inizde indirip çalıştırabileceğiniz, kullanımı kolay bir komut dosyası bulacaksınız. Bir web sitesini tarayabilir ve bir anahtar kelime listesini dışa aktarabilirseniz, bu komut dosyasını kullanabilirsiniz. Python’u yeni öğreniyorsanız bu mükemmel. Ve daha maceracı hissediyorsanız, kod dökümü ve açıklamaları ile birlikte takip edebilirsiniz.
Bu Python betiği, manuel çalışmanın çoğunu kaldırarak bu fırsatları bulmak için gereken süreyi azaltır. Fırsatların geçerli olup olmadığını kontrol ederek ilk veri analizini bile hallediyor. Bu, orta/büyük bir web sitesine sahip olan herkes için ve bu süreci kısa sürede çok sayıda müşteri için otomatikleştirmek isteyen ajanslar için yararlıdır. İşte bugün yapacağımız şeye bir örnek:

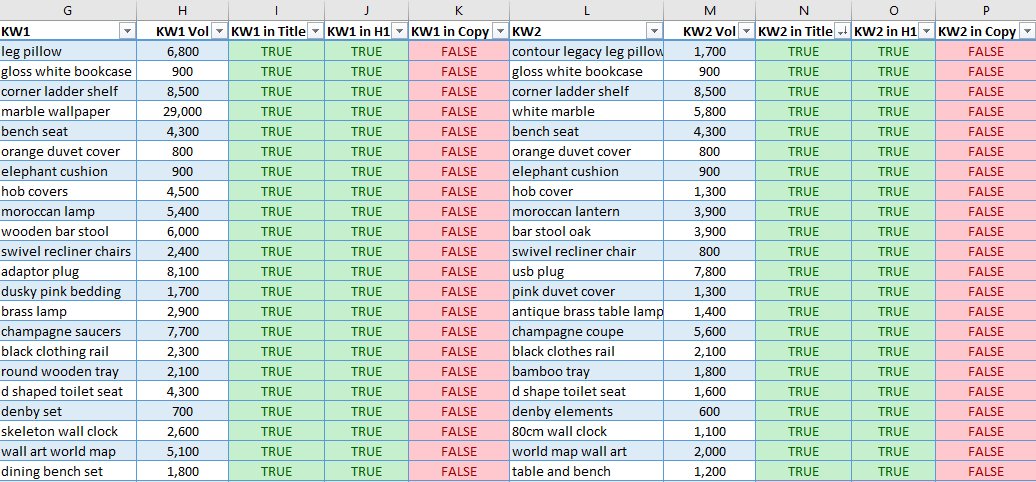
Bu anahtar kelimeler sayfa başlığında ve H1’de bulunur, ancak kopyada bulunmaz . Bu anahtar kelimeleri doğal olarak mevcut kopyaya eklemek, bu anahtar kelimeler için alaka düzeyini artırmanın kolay bir yolu olacaktır. Arama motorlarından ipucu alarak ve doğal olarak bir sitenin zaten sıraladığı eksik anahtar kelimeleri dahil ederek, arama motorlarının bu anahtar kelimeleri SERP’lerde daha üst sıralara koyma güvenini artırıyoruz. Bu rapor manuel olarak oluşturulabilir, ancak oldukça zaman alıcıdır. Bu yüzden bir Python SEO betiği kullanarak süreci otomatikleştireceğiz.
Çıktının Önizlemesi
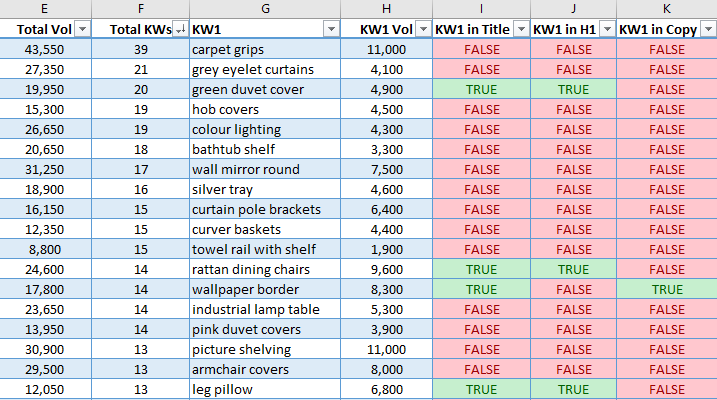
Bu, raporu çalıştırdıktan sonra nihai çıktının nasıl görüneceğinin bir örneğidir:

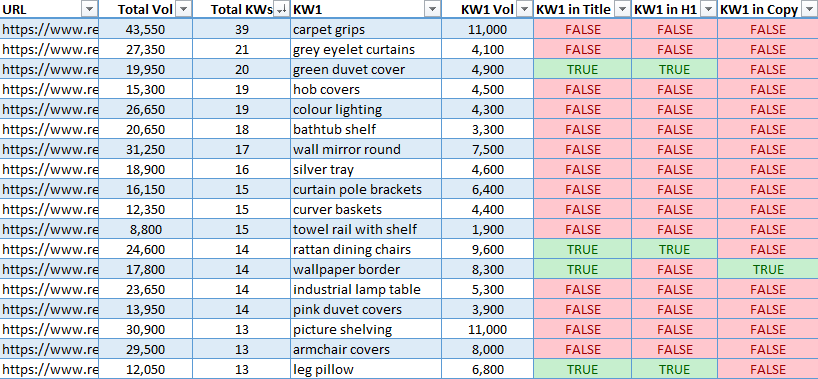
Nihai çıktı, her sayfa için arama hacmine göre ilk beş fırsatı alır ve her birini tahmini arama hacmiyle birlikte düzgün bir şekilde yatay olarak yerleştirir. Ayrıca, bir sayfanın dikkat çekici mesafesindeki tüm anahtar kelimelerin toplam arama hacminin yanı sıra, ulaşılabilen toplam anahtar kelime sayısını da gösterir. Arama hacmine göre ilk beş anahtar kelime daha sonra başlıkta, H1’de veya kopyada bulunup bulunmadığı kontrol edilir, ardından DOĞRU veya YANLIŞ olarak işaretlenir. Bu, hızlı kazançlar bulmak için harika! Eksik anahtar kelimeyi doğal olarak sayfa kopyasına, başlığa veya H1’e eklemeniz yeterlidir.
Başlarken
Kurulum oldukça basittir. Yalnızca sitenin taranmasına (ideal olarak kontrol etmek istediğiniz kopya için özel bir çıkarma ile) ve bir sitenin sıraladığı tüm anahtar kelimelerin dışa aktarılmış bir dosyasına ihtiyacımız var. Bu gönderi, kurulumda ve kodda size yol gösterecek ve kendiniz kodlamadan sadece takılmak istiyorsanız bir Google İşbirliği sayfasına bağlantı verecektir. Başlamak için ihtiyacınız olacak:
- Web Sitesinin bir taraması.
- Bir sitenin sıraladığı tüm anahtar kelimelerin dışa aktarımı.
- Tarama ve anahtar kelime verilerini birleştirmek için bu Google Colab sayfası .
Çarpma mesafesinde kolayca bulunan anahtar kelimeleri işaretlediği için buna Çarpıcı Mesafe Raporu adını verdik. (4-20 arasındaki konumlarda yer alan anahtar kelimeler olarak çarpıcı mesafeyi tanımladık, ancak kendi parametrelerinizi tanımlamak istemeniz durumunda bunu yapılandırılabilir bir seçenek haline getirdik.)
Çarpıcı SEO Raporu: Başlarken
1. Hedef Web Sitesini Tara
- Sayfa kopyası için özel bir çıkarıcı ayarlayın (isteğe bağlı, ancak önerilir).
- Sayfalandırma sayfalarını taramadan filtreleyin.
2. Sitenin Favori Sağlayıcınızı Kullandığı Sıradaki Tüm Anahtar Kelimeleri Dışa Aktarın
- Site bağlantısı olarak tetiklenen anahtar kelimeleri filtreleyin.
- Resim olarak tetikleyen anahtar kelimeleri kaldırın.
- Markalı anahtar kelimeleri filtreleyin.
- Anahtar kelimeden eyleme geçirilebilir bir Çarpıcı Mesafe raporu oluşturmak için her iki dışa aktarmayı da kullanın ve Python ile verileri tarayın.
Siteyi Tarama
İlk taramayı yapmak için Screaming Frog’u kullanmayı seçtim. CSV dışa aktarma aynı sütun adlarını kullandığı veya eşleşecek şekilde yeniden adlandırıldıkları sürece herhangi bir tarayıcı çalışır. Komut dosyası, tarama CSV dışa aktarımında aşağıdaki sütunları bulmayı umuyor:
"Address", "Title 1", "H1-1", "Copy 1", "Indexability"
Tarama Ayarları
Yapılacak ilk şey, Screaming Frog içindeki ana yapılandırma ayarlarına gitmektir: Yapılandırma > Örümcek > Tarama Kullanılacak ana ayarlar şunlardır: Dahili Bağlantıları , Kurallıları ve Sayfalandırma (Rel Next/Prev) ayarını tarayın . (Komut dosyası seçilen diğer her şeyle çalışacak, ancak taramanın tamamlanması daha uzun sürecek!)

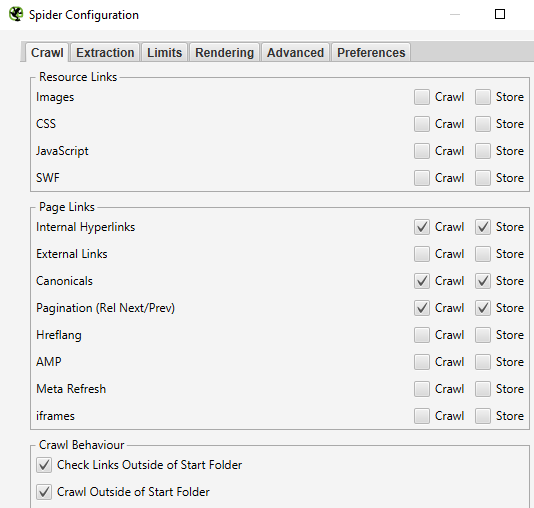
Ardından, Çıkarma sekmesine gelir. Yapılandırma > Örümcek > Çıkarma

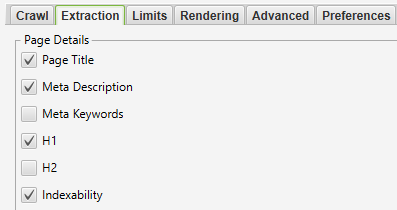
En azından, sayfa başlığı H1’i çıkarmamız ve sayfanın aşağıda gösterildiği gibi dizine eklenebilir olup olmadığını hesaplamamız gerekiyor. Dizine eklenebilirlik, komut dosyasının tek seferde hangi URL’lerin bırakılacağını belirlemesinin kolay bir yolu olduğundan, yalnızca SERP’lerde sıralamaya uygun anahtar kelimeleri bırakarak yararlıdır. Komut dosyası dizine eklenebilirlik sütununu bulamazsa, normal şekilde çalışmaya devam eder ancak sıralanabilen ve sıralanamayan sayfalar arasında ayrım yapmayacaktır.
Sayfa Kopyalama İçin Özel Bir Çıkarıcı Ayarlama
Sayfa kopyasında bir anahtar kelime bulunup bulunmadığını kontrol etmek için, Screaming Frog’da özel bir çıkarıcı ayarlamamız gerekiyor . Yapılandırma > Özel > Çıkarma Çıkarıcıyı aşağıda görüldüğü gibi “Kopyala” olarak adlandırın.

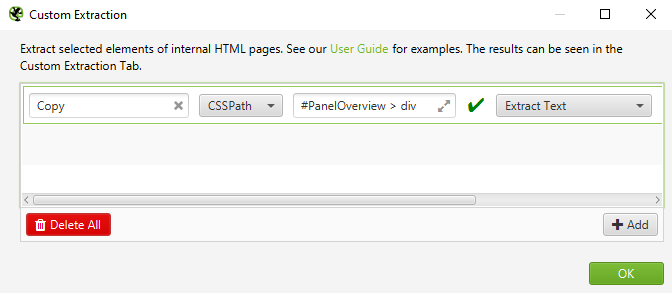
Önemli: Betik, çıkarıcının yukarıdaki gibi “Kopyala” olarak adlandırılmasını bekler, bu yüzden lütfen iki kez kontrol edin! Son olarak, kopyayı HTML yerine metin olarak dışa aktarmak için Metni Ayıkla’nın seçili olduğundan emin olun . Birini ayarlamak için yardıma ihtiyacınız varsa, özel çıkarıcıları çevrimiçi olarak kullanma konusunda birçok kılavuz var, bu yüzden burada tekrar üzerinde durmayacağım. Çıkarma ayarlandıktan sonra, siteyi taramanın ve HTML dosyasını CSV formatında dışa aktarmanın zamanı geldi.
CSV Dosyasını Dışa Aktarma
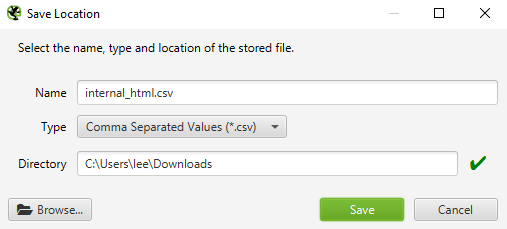
CSV dosyasını dışa aktarmak, Dahili altında görüntülenen açılır menüyü HTML’ye değiştirmek ve Dışa Aktar düğmesine basmak kadar kolaydır . Dahili > HTML > Dışa Aktar


Dışa Aktar ‘ ı tıkladıktan sonra , türün CSV biçimine ayarlandığından emin olmak önemlidir. Dışa aktarma ekranı aşağıdaki gibi görünmelidir:

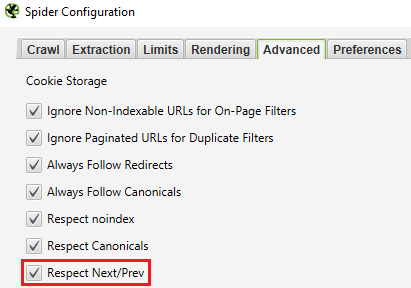
İpucu 1: Sayfalandırma Sayfalarını Filtreleme
Sayfalandırma sayfalarını , Gelişmiş ayarlar altında İleriye/Önceye Saygı’yı seçerek (veya isterseniz bunları yalnızca CSV dosyasından silerek) taramanızdan filtrelemenizi öneririm.

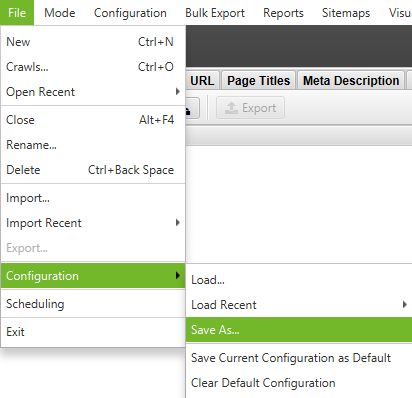
2. İpucu: Tarama Ayarlarını Kaydetme
Taramayı ayarladıktan sonra, tarama ayarlarını kaydetmeye değer (bu, aynı zamanda özel çıkarmayı da hatırlayacaktır). Komut dosyasını gelecekte tekrar kullanmak isterseniz, bu çok zaman kazandıracaktır. Dosya > Yapılandırma > Farklı Kaydet

Anahtar Kelimeleri Dışa Aktarma
Tarama dosyasına sahip olduğumuzda, bir sonraki adım, favori anahtar kelime araştırma aracınızı yüklemek ve bir sitenin sıraladığı tüm anahtar kelimeleri dışa aktarmaktır. Buradaki amaç, bir sitenin sıraladığı tüm anahtar kelimeleri dışa aktarmak, markalı anahtar kelimeleri ve site bağlantısı veya resim olarak tetiklenenleri filtrelemektir. Bu örnek için Ahrefs’teki Organik Anahtar Kelime Raporunu kullanıyorum ancak tercih ettiğiniz araç buysa, Semrush ile de aynı şekilde çalışacaktır. Ahrefs’te, kontrol etmek istediğiniz etki alanını Site Gezgini’ne girin ve Organik Anahtar Kelimeler’i seçin .


Site Gezgini > Organik Anahtar Kelimeler

Bu, sitenin sıraladığı tüm anahtar kelimeleri getirecektir.
Site Bağlantılarını ve Resim Bağlantılarını Filtreleme
Sonraki adım, site bağlantısı veya resim paketi olarak tetiklenen tüm anahtar kelimeleri filtrelemektir. Site bağlantılarını filtrelememizin nedeni, bunların üst URL sıralaması üzerinde hiçbir etkilerinin olmamasıdır. Bunun nedeni, anahtar kelimenin altında görüntülenen site bağlantısı URL’lerinin değil, yalnızca ana sayfanın teknik olarak sıralanmasıdır. Site bağlantılarını filtrelemek, doğru sayfayı optimize etmemizi sağlayacaktır.

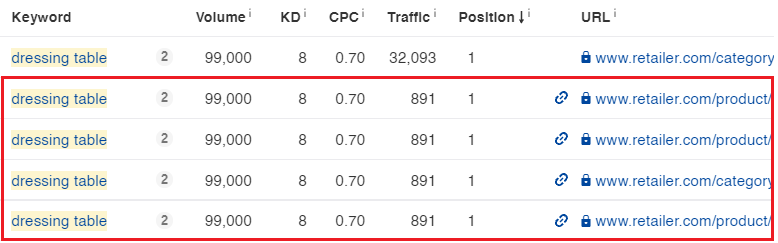
Ahrefs’te bunu nasıl yapacağınız aşağıda açıklanmıştır.

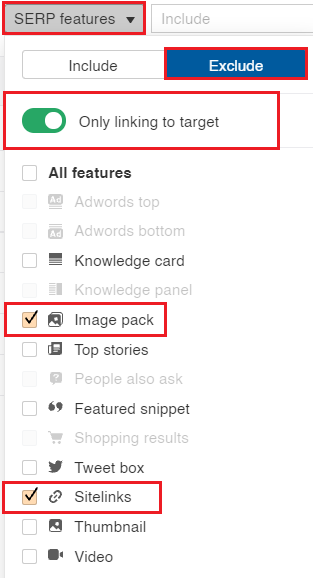
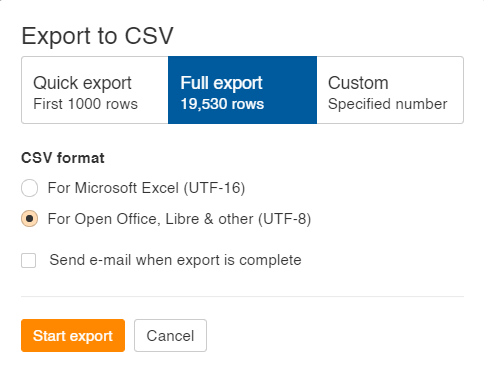
Son olarak, markalı anahtar kelimeleri filtrelemenizi öneririm. Bunu, doğrudan CSV çıktısını filtreleyerek veya dışa aktarmadan önce seçtiğiniz anahtar kelime aracında ön filtreleme yaparak yapabilirsiniz. Son olarak, dışa aktarırken aşağıda gösterildiği gibi Tam Dışa Aktarma ve UTF-8 biçimini seçtiğinizden emin olun .

Varsayılan olarak, komut dosyası Ahrefs (v1/v2) ve Semrush anahtar kelime dışa aktarmalarıyla çalışır. Komut dosyasının beklediği sütun adları mevcut olduğu sürece herhangi bir anahtar kelime CSV dosyasıyla çalışabilir.
İşleme
Artık dışa aktarılan dosyalarımıza sahip olduğumuza göre, yapılması gereken tek şey onları işlenmek üzere Google İşbirliği sayfasına yüklemek . Sayfadaki tüm hücreleri çalıştırmak için üstteki gezinmeden Çalışma Zamanı > Tümünü çalıştır’ı seçin .

Komut dosyası, önce Ahrefs veya Semrush’tan CSV anahtar sözcüğünü ve ardından tarama dosyasını yüklemenizi ister.


Bu kadar! Komut dosyası, sitenizi optimize etmek için kullanabileceğiniz işlem yapılabilir bir CSV dosyasını otomatik olarak indirecektir.

Tüm sürece aşina olduğunuzda, komut dosyasını kullanmak gerçekten basittir.
Kod Dökümü ve Açıklama
SEO için Python öğreniyorsanız ve raporu oluşturmak için kodun ne yaptığıyla ilgileniyorsanız, kod adım adım izleyin!
Kitaplıkları Yükle
Topu yuvarlamak için yerleştirelim.
!pip install pandas
Modülleri İçe Aktar
Ardından, gerekli modülleri içe aktarmamız gerekiyor.
import pandas as pd from pandas import DataFrame, Series from typing import Union from google.colab import files
Değişkenleri Ayarla
Şimdi değişkenleri ayarlama zamanı. Senaryo, 4. ve 20. konumlar arasındaki tüm anahtar kelimeleri çarpıcı bir mesafe içinde kabul eder. Buradaki değişkenleri değiştirmek, isterseniz kendi aralığınızı tanımlamanıza izin verecektir. İhtiyaçlarınız için mümkün olan en iyi çıktıyı elde etmek için ayarları denemeye değer.
# set all variables here min_volume = 10 # set the minimum search volume min_position = 4 # set the minimum position / default = 4 max_position = 20 # set the maximum position / default = 20 drop_all_true = True # If all checks (h1/title/copy) are true, remove the recommendation (Nothing to do) pagination_filters = "filterby|page|p=" # filter patterns used to detect and drop paginated pages
Anahtar Kelime Dışa Aktarma CSV Dosyasını Yükleyin
Bir sonraki adım, CSV dosyasındaki anahtar kelimeler listesini okumaktır. Ahrefs raporunu (V1 ve V2) ve Semrush ihracatını kabul edecek şekilde ayarlanmıştır. Bu kod, CSV dosyasında Pandas DataFrame’e okur.
upload = files.upload()
upload = list(upload.keys())[0]
df_keywords = pd.read_csv(
(upload),
error_bad_lines=False,
low_memory=False,
encoding="utf8",
dtype={
"URL": "str",
"Keyword": "str",
"Volume": "str",
"Position": int,
"Current URL": "str",
"Search Volume": int,
},
)
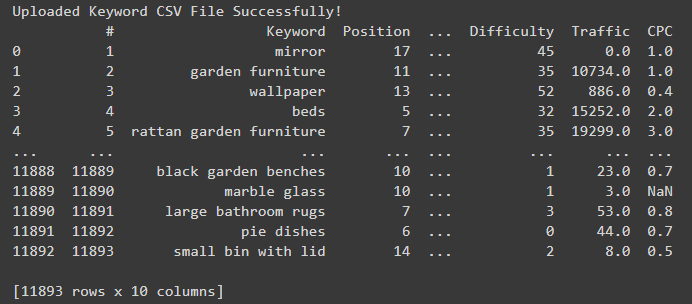
print("Uploaded Keyword CSV File Successfully!")Her şey planlandığı gibi gittiyse, CSV dışa aktarma anahtar kelimesinden oluşturulan DataFrame’in bir önizlemesini görürsünüz.

Tarama Dışa Aktarma CSV Dosyasını Yükleyin
Anahtar kelimeler içe aktarıldıktan sonra, tarama dosyasını yükleme zamanı gelir.
This fairly simple piece of code reads in the crawl with some error handling option and creates a Pandas DataFrame named df_crawl.
upload = files.upload()
upload = list(upload.keys())[0]
df_crawl = pd.read_csv(
(upload),
error_bad_lines=False,
low_memory=False,
encoding="utf8",
dtype="str",
)
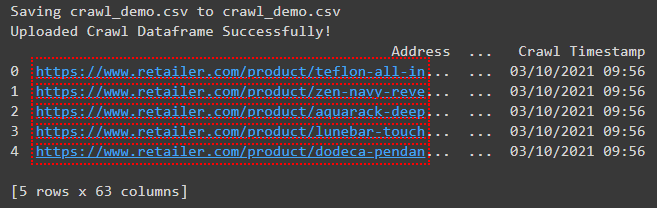
print("Uploaded Crawl Dataframe Successfully!")CSV dosyasının yüklenmesi bittiğinde, DataFrame’in bir önizlemesini göreceksiniz.

Anahtar Kelime Verilerini Temizleyin ve Standartlaştırın
Sonraki adım, en yaygın dosya dışa aktarma türleri arasında standardizasyonu sağlamak için sütun adlarını yeniden adlandırmaktır. Esasen, veri çerçevesi anahtar kelimesini iyi bir duruma getiriyoruz ve değişkenler tarafından tanımlanan kesimleri kullanarak filtreleme yapıyoruz.
df_keywords.rename(
columns={
"Current position": "Position",
"Current URL": "URL",
"Search Volume": "Volume",
},
inplace=True,
)
# keep only the following columns from the keyword dataframe
cols = "URL", "Keyword", "Volume", "Position"
df_keywords = df_keywords.reindex(columns=cols)
try:
# clean the data. (v1 of the ahrefs keyword export combines strings and ints in the volume column)
df_keywords["Volume"] = df_keywords["Volume"].str.replace("0-10", "0")
except AttributeError:
pass
# clean the keyword data
df_keywords = df_keywords[df_keywords["URL"].notna()] # remove any missing values
df_keywords = df_keywords[df_keywords["Volume"].notna()] # remove any missing values
df_keywords = df_keywords.astype({"Volume": int}) # change data type to int
df_keywords = df_keywords.sort_values(by="Volume", ascending=False) # sort by highest vol to keep the top opportunity
# make new dataframe to merge search volume back in later
df_keyword_vol = df_keywords[["Keyword", "Volume"]]
# drop rows if minimum search volume doesn't match specified criteria
df_keywords.loc[df_keywords["Volume"] < min_volume, "Volume_Too_Low"] = "drop"
df_keywords = df_keywords[~df_keywords["Volume_Too_Low"].isin(["drop"])]
# drop rows if minimum search position doesn't match specified criteria
df_keywords.loc[df_keywords["Position"] <= min_position, "Position_Too_High"] = "drop"
df_keywords = df_keywords[~df_keywords["Position_Too_High"].isin(["drop"])]
# drop rows if maximum search position doesn't match specified criteria
df_keywords.loc[df_keywords["Position"] >= max_position, "Position_Too_Low"] = "drop"
df_keywords = df_keywords[~df_keywords["Position_Too_Low"].isin(["drop"])]Tarama Verilerini Temizleyin ve Standartlaştırın
Ardından, tarama verilerini temizlememiz ve standartlaştırmamız gerekiyor. Esasen, reindex’i yalnızca “Adres”, “Dizinlenebilirlik”, “Sayfa Başlığı”, “H1-1” ve “Kopya 1” sütunlarını tutmak ve geri kalanını atmak için kullanırız. Kullanışlı “Dizinlenebilirlik” sütununu yalnızca dizine eklenebilir satırları tutmak için kullanıyoruz. Bu, kurallı URL’leri, yönlendirmeleri vb. bırakacaktır. Taramada bu seçeneği etkinleştirmenizi öneririm. Son olarak, sütun adlarını standartlaştırdık, böylece birlikte çalışmak biraz daha hoş olacak.
# keep only the following columns from the crawl dataframe
cols = "Address", "Indexability", "Title 1", "H1-1", "Copy 1"
df_crawl = df_crawl.reindex(columns=cols)
# drop non-indexable rows
df_crawl = df_crawl[~df_crawl["Indexability"].isin(["Non-Indexable"])]
# standardise the column names
df_crawl.rename(columns={"Address": "URL", "Title 1": "Title", "H1-1": "H1", "Copy 1": "Copy"}, inplace=True)
df_crawl.head()Anahtar Kelimeleri Gruplandırın
Nihai çıktıya yaklaşırken, her sayfa için toplam fırsatı hesaplamak için anahtar kelimelerimizi birlikte gruplandırmamız gerekiyor. Burada, birleşik arama hacmiyle birlikte her bir sayfa için dikkat çekici mesafede kaç anahtar kelime olduğunu hesaplıyoruz.
# groups the URLs (remove the dupes and combines stats)
# make a copy of the keywords dataframe for grouping - this ensures stats can be merged back in later from the OG df
df_keywords_group = df_keywords.copy()
df_keywords_group["KWs in Striking Dist."] = 1 # used to count the number of keywords in striking distance
df_keywords_group = (
df_keywords_group.groupby("URL")
.agg({"Volume": "sum", "KWs in Striking Dist.": "count"})
.reset_index()
)
df_keywords_group.head()
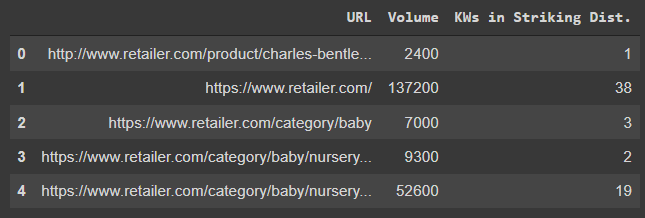
Tamamlandığında, DataFrame’in bir önizlemesini göreceksiniz.
Anahtar Kelimeleri Bitişik Satırlarda Görüntüle
Gruplandırılmış verileri nihai çıktı için temel olarak kullanırız. Anahtar kelimeleri bir GrepWords dışa aktarma stilinde görüntülemek için DataFrame’i yeniden şekillendirmek için Pandas.unstack kullanıyoruz.

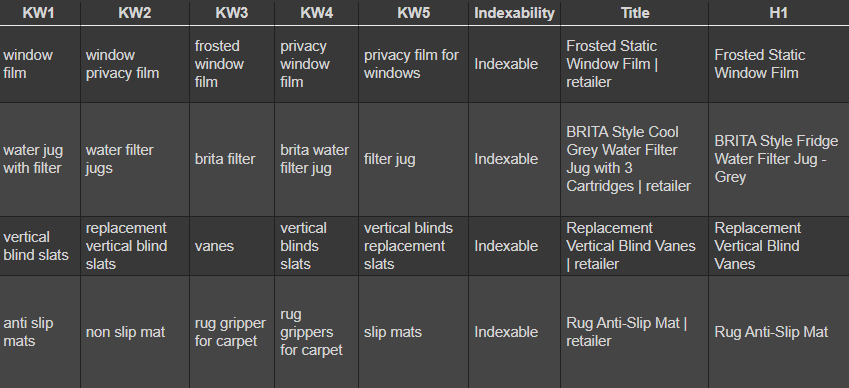
# create a new df, combine the merged data with the original data. display in adjacent rows ala grepwords
df_merged_all_kws = df_keywords_group.merge(
df_keywords.groupby("URL")["Keyword"]
.apply(lambda x: x.reset_index(drop=True))
.unstack()
.reset_index()
)
# sort by biggest opportunity
df_merged_all_kws = df_merged_all_kws.sort_values(
by="KWs in Striking Dist.", ascending=False
)
# reindex the columns to keep just the top five keywords
cols = "URL", "Volume", "KWs in Striking Dist.", 0, 1, 2, 3, 4
df_merged_all_kws = df_merged_all_kws.reindex(columns=cols)
# create union and rename the columns
df_striking: Union[Series, DataFrame, None] = df_merged_all_kws.rename(
columns={
"Volume": "Striking Dist. Vol",
0: "KW1",
1: "KW2",
2: "KW3",
3: "KW4",
4: "KW5",
}
)
# merges striking distance df with crawl df to merge in the title, h1 and category description
df_striking = pd.merge(df_striking, df_crawl, on="URL", how="inner")Son Sütun Sırasını Belirleme ve Yer Tutucu Sütunları Ekleme
Son olarak, son sütun sırasını belirledik ve orijinal anahtar kelime verilerinde birleştirdik. Sıralanacak ve oluşturulacak çok sayıda sütun var!
# set the final column order and merge the keyword data in cols = [ "URL", "Title", "H1", "Copy", "Striking Dist. Vol", "KWs in Striking Dist.", "KW1", "KW1 Vol", "KW1 in Title", "KW1 in H1", "KW1 in Copy", "KW2", "KW2 Vol", "KW2 in Title", "KW2 in H1", "KW2 in Copy", "KW3", "KW3 Vol", "KW3 in Title", "KW3 in H1", "KW3 in Copy", "KW4", "KW4 Vol", "KW4 in Title", "KW4 in H1", "KW4 in Copy", "KW5", "KW5 Vol", "KW5 in Title", "KW5 in H1", "KW5 in Copy", ] # re-index the columns to place them in a logical order + inserts new blank columns for kw checks. df_striking = df_striking.reindex(columns=cols)
Her Sütun İçin Anahtar Kelime Verilerinde Birleştirme
Bu kod, anahtar sözcük hacim verilerini DataFrame’de birleştirir. Bu, aşağı yukarı bir Excel DÜŞEYARA işlevinin eşdeğeridir.
# merge in keyword data for each keyword column (KW1 - KW5) df_striking = pd.merge(df_striking, df_keyword_vol, left_on="KW1", right_on="Keyword", how="left") df_striking['KW1 Vol'] = df_striking['Volume'] df_striking.drop(['Keyword', 'Volume'], axis=1, inplace=True) df_striking = pd.merge(df_striking, df_keyword_vol, left_on="KW2", right_on="Keyword", how="left") df_striking['KW2 Vol'] = df_striking['Volume'] df_striking.drop(['Keyword', 'Volume'], axis=1, inplace=True) df_striking = pd.merge(df_striking, df_keyword_vol, left_on="KW3", right_on="Keyword", how="left") df_striking['KW3 Vol'] = df_striking['Volume'] df_striking.drop(['Keyword', 'Volume'], axis=1, inplace=True) df_striking = pd.merge(df_striking, df_keyword_vol, left_on="KW4", right_on="Keyword", how="left") df_striking['KW4 Vol'] = df_striking['Volume'] df_striking.drop(['Keyword', 'Volume'], axis=1, inplace=True) df_striking = pd.merge(df_striking, df_keyword_vol, left_on="KW5", right_on="Keyword", how="left") df_striking['KW5 Vol'] = df_striking['Volume'] df_striking.drop(['Keyword', 'Volume'], axis=1, inplace=True)
Verileri Biraz Daha Temizleyin
Veriler, boş değerleri (NaN’ler) boş dizeler olarak doldurmak için ek temizleme gerektirir. Bu, NaN dize değerleriyle doldurulmuş hücreler yerine boş hücreler oluşturarak nihai çıktının okunabilirliğini artırır. Ardından, belirli bir sütunda bir hedef anahtar kelimenin öne çıkıp çıkmadığını kontrol ederken eşleşmeleri için sütunları küçük harfe dönüştürürüz.
# replace nan values with empty strings
df_striking = df_striking.fillna("")
# drop the title, h1 and category description to lower case so kws can be matched to them
df_striking["Title"] = df_striking["Title"].str.lower()
df_striking["H1"] = df_striking["H1"].str.lower()
df_striking["Copy"] = df_striking["Copy"].str.lower()Anahtar Kelimenin Başlıkta/H1/Kopyalamada Görünüp Görünmediğini Kontrol Edin ve Doğru mu Yanlış mı Döndürün
Bu kod, hedef anahtar kelimenin sayfa başlığında / h1’de veya kopyada bulunup bulunmadığını kontrol eder. Sayfadaki öğelerde bir anahtar kelimenin bulunup bulunmadığına bağlı olarak doğru veya yanlış olarak işaretler.
df_striking["KW1 in Title"] = df_striking.apply(lambda row: row["KW1"] in row["Title"], axis=1) df_striking["KW1 in H1"] = df_striking.apply(lambda row: row["KW1"] in row["H1"], axis=1) df_striking["KW1 in Copy"] = df_striking.apply(lambda row: row["KW1"] in row["Copy"], axis=1) df_striking["KW2 in Title"] = df_striking.apply(lambda row: row["KW2"] in row["Title"], axis=1) df_striking["KW2 in H1"] = df_striking.apply(lambda row: row["KW2"] in row["H1"], axis=1) df_striking["KW2 in Copy"] = df_striking.apply(lambda row: row["KW2"] in row["Copy"], axis=1) df_striking["KW3 in Title"] = df_striking.apply(lambda row: row["KW3"] in row["Title"], axis=1) df_striking["KW3 in H1"] = df_striking.apply(lambda row: row["KW3"] in row["H1"], axis=1) df_striking["KW3 in Copy"] = df_striking.apply(lambda row: row["KW3"] in row["Copy"], axis=1) df_striking["KW4 in Title"] = df_striking.apply(lambda row: row["KW4"] in row["Title"], axis=1) df_striking["KW4 in H1"] = df_striking.apply(lambda row: row["KW4"] in row["H1"], axis=1) df_striking["KW4 in Copy"] = df_striking.apply(lambda row: row["KW4"] in row["Copy"], axis=1) df_striking["KW5 in Title"] = df_striking.apply(lambda row: row["KW5"] in row["Title"], axis=1) df_striking["KW5 in H1"] = df_striking.apply(lambda row: row["KW5"] in row["H1"], axis=1) df_striking["KW5 in Copy"] = df_striking.apply(lambda row: row["KW5"] in row["Copy"], axis=1)
Anahtar Kelime Yok ise Doğru/Yanlış Değerleri Sil
Bu, bitişik anahtar kelime olmadığında doğru/yanlış değerleri siler.
# delete true / false values if there is no keyword df_striking.loc[df_striking["KW1"] == "", ["KW1 in Title", "KW1 in H1", "KW1 in Copy"]] = "" df_striking.loc[df_striking["KW2"] == "", ["KW2 in Title", "KW2 in H1", "KW2 in Copy"]] = "" df_striking.loc[df_striking["KW3"] == "", ["KW3 in Title", "KW3 in H1", "KW3 in Copy"]] = "" df_striking.loc[df_striking["KW4"] == "", ["KW4 in Title", "KW4 in H1", "KW4 in Copy"]] = "" df_striking.loc[df_striking["KW5"] == "", ["KW5 in Title", "KW5 in H1", "KW5 in Copy"]] = "" df_striking.head()
Tüm Değerler == Doğru ise Satırları Bırak
Bu yapılandırılabilir seçenek, anahtar kelime fırsatını üç sütunda da bulunursa, nihai çıktıdan çıkararak nihai çıktı için gereken QA süresini azaltmak için gerçekten kullanışlıdır.
def true_dropper(col1, col2, col3):
drop = df_striking.drop(
df_striking[
(df_striking[col1] == True)
& (df_striking[col2] == True)
& (df_striking[col3] == True)
].index
)
return drop
if drop_all_true == True:
df_striking = true_dropper("KW1 in Title", "KW1 in H1", "KW1 in Copy")
df_striking = true_dropper("KW2 in Title", "KW2 in H1", "KW2 in Copy")
df_striking = true_dropper("KW3 in Title", "KW3 in H1", "KW3 in Copy")
df_striking = true_dropper("KW4 in Title", "KW4 in H1", "KW4 in Copy")
df_striking = true_dropper("KW5 in Title", "KW5 in H1", "KW5 in Copy")CSV Dosyasını İndirin
Son adım, CSV dosyasını indirmek ve optimizasyon sürecini başlatmaktır.
df_striking.to_csv('Keywords in Striking Distance.csv', index=False)
files.download("Keywords in Striking Distance.csv")
